99/08/14
This SMP program was written in C++Builder 4. The full project source and EXE file can be downloaded by clicking here (318KB).
SMP Introduction
SMP (or symmetric multiprocessing) is an Intel and Microsoft standard for gluing several CPUs onto one memory and I/O bus. I have been making use of it for an image processing application and needed a way to test performance on different platforms. This program can give you an idea about how fast your raw memory speed is. It doesn't really tell you how well your SQL server will run on the latest quad Zeon box, but it can tell you the potential for performance. It is geared more toward showing how well memory intensive compute bound applications will perform on your hardware.
The Intel Pentium processors have been designed to allow placing several of them onto a memory bus at the same time while controlling access to memory and the PCI I/O bus. The Pentium II and III could connect up to 2 processors on the same physical bus. To get more of them together you needed custom glue chips which have not been a big success due to the increased gate delays. The Zeon processor has been designed with a bus that can accept up to 4 processors at a time. The bus speed has also been increased from 66 MHz to 100 MHz on the newest systems. The main limitation in image processing is the memory bus speed. If you get all 4 processors running a simple image processing command they can end up waiting for memory accesses and not scale up in a linear fashion.
Most programs read, process and write memory locations. Depending on how complex the processing is, the processor may be able to cache all the instructions in a loop and only make the read and write accesses to the data. This program performs several of these types of tests. The speed of execution is limited only by how fast the memory bus is. A typical SQL database application may perform calculations and operate disk and network subsystem cards as well, and this test wasn't designed to check how well your system will scale when running these programs.
I was more interested in how fast I could perform operations on image buffers in memory. Such operations can get very complex and for this program I followed the KISS (keep it simple stupid) design mode. The only image operations I perform are a simple image histogram and an in-place threshold. Other image operations tend to become ALU and memory access bound unless you program them in MMX, which I didn't do. These operations make use of simple loops and byte data access. They could be optimized by making 32-bit accesses, but I wanted to see the basic byte bus speed. Several different memory read, write and read-modify-write tests are provided. They have been optimized in assembly and C++ code so we can see if assembly is worth messing with.
I might add that getting the C++ code to run both correctly and fast was a major problem. You need to be very careful how you use the language or else the compiler will eliminate code when optimizations are turned on and give false readings. This is why you will see use of the volatile keyword on some variables, otherwise the code gets optimized away.
I will also admit that there may be faster ways to use assembly language. I did some testing and found some processor specific surprises with different assembly codes (fully discussed later). For example, you would normally think that the REP LODSB instruction would be faster than the memory reading code I used. Not true - at least on the Pentium 233 where I tested it. The code I used reads memory about 25% faster than the so called processor optimized string instructions.
I do not recommend running this test unless you have at least a dual 300 MHz Pentium II. Slower machines may start to show increases in time due to processing speed. At 300 MHz you start to see the limitations of the PCI bus.
A Minor Warning!
The SMP test program runs at the HIGH process priority. When running your system at 100% it will stop many lower level programs from running (including the SQL server). You may not be able to switch to other programs or get them to respond, but you will always be able to stop the SMP program. You will also notice a slight delay when making changes to the program settings. It may require two mouse clicks to get something to happen. This is normal and you should give the mouse a rest after changes. The program runs in single processor mode during this time to determine the 100% level for one processor. Excessive mouse movements may affect the accuracy of this measurement.
Looking at the CPU Operation
This first screen shows the Windows Task Manager with one CPU intensive thread running. You can right click the start menu bar or press ctrl-alt-del to get into the Task Manager. In a dual processor system, a CPU bound thread will jump from one CPU to the other and divide the time between them. This is why the CPU Usage History is almost equal for the two processors.
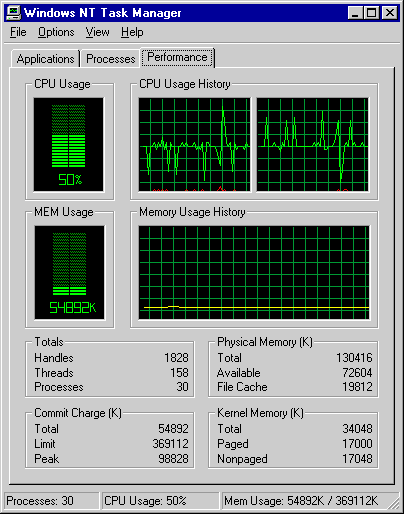
Screen 1: one cpu intensive thread.
We move the task control to the second position to start another thread running. Now both CPUs are working and we have full processor usage.
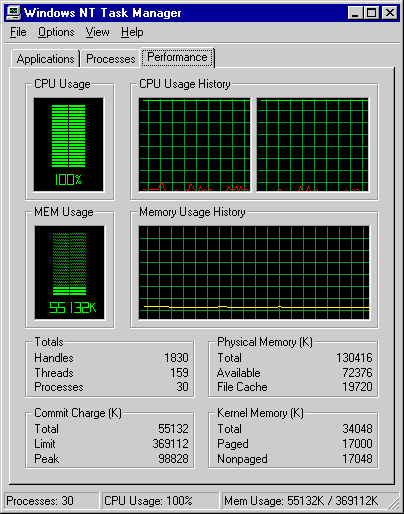
Screen 2: both cpus running threads.
The application is shown here running on one CPU. It is doing a loop of sine calculations without any memory access.
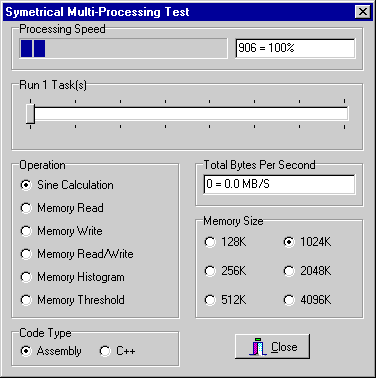
Screen 3: sine calculations on one cpu.
The application is shown here running on two CPUs. Because there is no memory access, both CPUs kick in and you get about twice as many program operations in the same time. The indicator may not show exactly 200% due to minor timing errors.
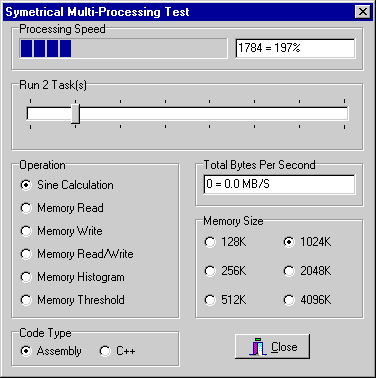
Screen 4: both cpus running sine calculations.
We now see what happens when we switch to memory read operations. The Pentium II processor has a 512K L2 memory cache. Because the memory size is 1024K, we are reading data directly from memory through the cache.
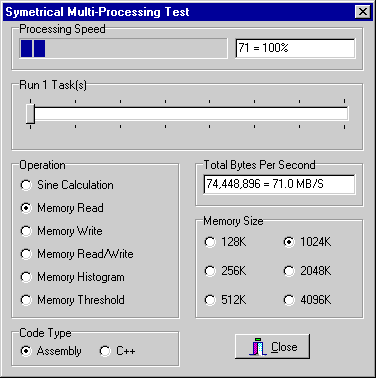
Screen 5: one cpu reading memory through cache.
We now switch the program into two processor mode. If we were not limited by the memory system we would expect to see an increase to 200% in processing speed. Instead we only get about 160% due to main memory speed limitations.
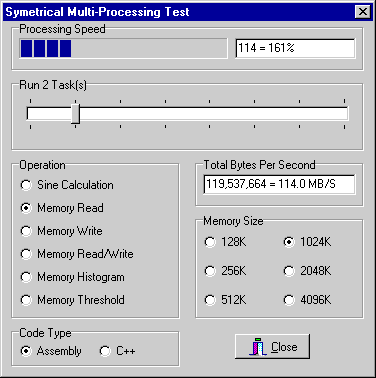
Screen 6: both cpus reading memory through cache.
The following table provides a summary of the dual processor memory access tests:
|
Test |
Language |
Memory Size |
Dual Processing Speed |
MB Per Second |
|
Memory Read |
Assembly |
1024K |
114 = 161% |
114.0 |
|
Memory Read |
Assembly |
256K |
1095 = 194% |
273.8 |
|
Memory Write |
Assembly |
1024K |
116 = 126% |
116.0 |
|
Memory Write |
Assembly |
256K |
755 = 200% |
188.8 |
|
Memory R/W |
Assembly |
1024K |
88 = 176% |
88.0 |
|
Memory R/W |
Assembly |
256K |
711 = 204% |
177.8 |
Table 1: Dual Processor Raw Byte Mode Memory Access Speed
When we switch to 256K memory blocks, we see the bytes per second take a large jump. With this size of memory access, the whole memory buffer gets cached. This is the raw speed at which we can read data out of the cache. It will scale by 200% because it is not bus limited.
When the buffer is larger than the cache, we are memory speed limited, and the performance will not increase as much. Notice that the memory write test provides the worst performance when not using the cache. Adding more processors won't help the situation here because we are limited by memory access speed.
The last test is a memory read-modify-write operation. While this doesn't reach the raw bus speed of the read or write tests, it doesn't cut the bytes per second performance quite in half. There appears to be some interleaving of the read-modify-write operations.
Image Processing Tests
These results are for the image histogram test. This test is reading the memory image buffer and using the value to index a 256 integer array and increment it. While the 256K memory buffer will fit in the cache, the integer array won't. The level of performance is not very good for any of these tests but they scale fairly well with 2 processors because we aren't pushing the memory performance too much.
Also, I test a C++ routine to process the histogram. It appears the hand crafted assembly code is not as fast as I thought it would be. I made sure to make use of registers to count and index the loops. The code is not as complex as the assembly code output by the C++ compiler - yet it is slower.
|
Test |
Language |
Memory Size |
Dual Processing Speed |
MB Per Second |
|
Memory Histogram |
Assembly |
1024K |
39 = 195% |
39.0 |
|
Memory Histogram |
C++ |
1024K |
64 = 178% |
64.0 |
|
Memory Histogram |
Assembly |
256K |
184 = 200% |
46.0 |
|
Memory Histogram |
C++ |
256K |
380 = 200% |
95.0 |
Table 2: Dual Processor Image Histogram Speed
After some checking I found that the assembly code ran faster on a Pentium 233 than it did on a Pentium II 300! Something odd is going on. Here is the code I first used:
mov edx,NBUF mov ebx,buf mov ecx,Histogram mov eax,0 step4: mov al,byte ptr [ebx] inc dword ptr [ecx+eax*4] inc ebx dec edx jnz step4
I figured that using the [ecx+eax*4] addressing mode would be simple and that the processor would execute it as fast as possible. It appears the different Pentium models execute the code in different ways and while one operates fast, the other doesn't. I played around with the code and found that I could speed it up greatly on both processors if I did some of the address calculation using a shift instead of a multiply. Here is the new code I settled on:
mov edx,NBUF mov ebx,buf mov ecx,Histogram step4: xor eax,eax mov al,byte ptr [ebx] shl eax,2 inc dword ptr [ecx+eax] inc ebx dec edx jnz step4
It is now much faster on the Pentium II 300, but is slower than the C++ code on the Pentium 233. It would appear that the Pentium 233 optimized the original address calculation while the Pentium II didn't. It seems that you can't win the optimization game unless you optimize for each processor. Here is a table of results with the new code:
|
Test |
Language |
Memory Size |
Dual Processing Speed |
MB Per Second |
|
Memory Histogram |
Assembly |
1024K |
72 = 185% |
72.0 |
|
Memory Histogram |
C++ |
1024K |
64 = 178% |
64.0 |
|
Memory Histogram |
Assembly |
256K |
421 = 200% |
105.3 |
|
Memory Histogram |
C++ |
256K |
380 = 200% |
95.0 |
Table 3: Dual Processor Image Histogram Speed
The next table shows results for the memory threshold test. This is mostly a memory read-compare-write test and should provide results similar to the read-modify-write times.
|
Test |
Language |
Memory Size |
Dual Processing Speed |
MB Per Second |
|
Memory Threshold |
Assembly |
1024K |
80 = 178% |
80.0 |
|
Memory Threshold |
C++ |
1024K |
64 = 178% |
64.0 |
|
Memory Threshold |
Assembly |
256K |
560 = 199% |
140.0 |
|
Memory Threshold |
C++ |
256K |
369 = 203% |
92.3 |
Table 4: Dual Processor Image Threshold Speed
Conclusion
While dual and quad processor systems carry a high price premium, we can see that the performance isn't always as great as we might expect. If your programs execute many small loops, and access small arrays of data, then the performance boost can be equal to the added processing power. In the real world, database server applications may keep their instructions cached during a query, but the data going through the CPU may consist of many megabytes of disk data. In this case, main memory bus speed will be the most important factor affecting your speed gain.
Image processing can fit into either model. Because most image processing libraries are starting to make use of MMX, these tests may not indicate the performance boost when using MMX. When a processor executes MMX instructions, it usually grabs 64-bit words from memory, processes them in the MMX mode and then writes them back. This type of program will usually be limited by memory performance and will not see a full performance increase when processors are added. My personal tests on one such MMX optimized image processing library shows a dual processor performance boost on some operations and none on others.
New advances in processor technology are helping this situation. The new Intel BX chipset increases the CPU-Memory bus speed to 100 MHz, and the Intel Zeon processor can be ordered with a much larger L2 cache than the Pentium III. While these features may help increase multiprocessing speed, certain types of programs will always be limited by the raw memory speed. Memory designs such as CPU local processing memory with a global N-way interconnect, seen on some DSP systems, seem to be a much better design to start with for highly scalable multiprocessing.